

By Nathan Donaldson
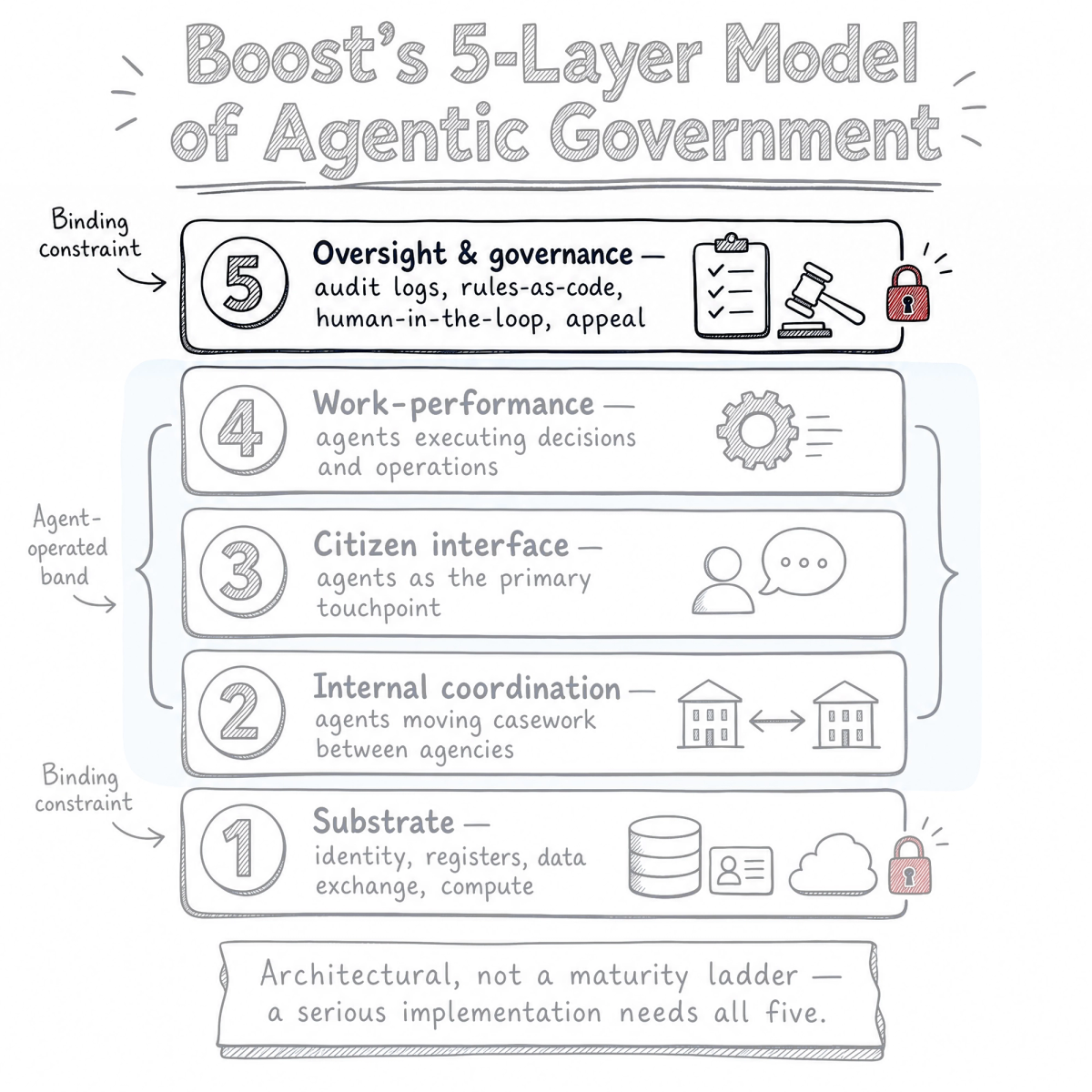
Boost's 5-layer model is a map of Agentic Government. This post is about layer 5, and it sets out the position the model holds most strongly.
Agentic AI is software that can chase goals on its own, not just answer one prompt at a time. The five layers, in brief:
The numbering is about parts, not steps. Today, layer 5.
Layer 5 is oversight and governance. Audit logs. A register of which agents are allowed to do what. Rules written as code. A human in the loop. A real right to appeal. An explanation a person can actually read.
The building analogy lands hardest here. Layer 5 is the building code, the fire inspection, and the certificate that says people are allowed in. A tower's height was never set by how high concrete can be poured. It was set by what the inspector will sign off. That is the point of this post. The thing that holds agentic government back is not how clever the models get. It is whether the oversight is good enough to let them run.
On this model, the binding constraint is oversight maturity, not model capability. Most of the debate, hopeful or worried, turns on whether the models are good enough. That is the wrong axis.
Start with the bar that already exists. In Estonia, every data exchange between agencies has been authenticated, signed, and logged for around twenty-five years. Who touched a record, and why, is traceable. That is a high bar, and it is the foundation's bar. It is built for data moving between systems.
Now raise the stakes. When an agent starts making the call on a person's benefit, or visa, or tax, the record of the agent's decision needs to be at least as trustworthy. Not "the data moved," but "here is what the agent decided, on what basis, and here is how a person challenges it." As far as Boost has been able to find, nothing at that standard runs in production anywhere, for agent decisions.
The ambition is on paper. The Agentic State paper describes a governance layer with an agent registry, kill switches, rollback history, and rules published as code next to the law they encode. The Tony Blair Institute offers a set of principles: predictability, explainability, accountability, reversibility, and sensitivity. These are good. Neither is a running production system.
What governments actually have is lighter than the ambition. The United Kingdom has a transparency register for algorithms, made mandatory for central departments in March 2024, with a few dozen records published in its first year. It is the most developed thing of its kind. But it is a disclosure list, not a binding audit or a right of appeal. The United Kingdom also has a voluntary AI playbook, and a private member's bill on automated decisions that has not become law. Aotearoa New Zealand has the Algorithm Charter, launched in 2020 as a world first, now signed by around thirty agencies. It is voluntary, and it does include a commitment to a channel for challenging decisions, which is the most specific promise of its kind. New Zealand also has a Better Rules programme, the most developed rules-as-code effort by intent, still at the discovery stage. Singapore has a voluntary governance framework for agentic AI. Estonia, as an EU member, will be bound by the EU AI Act's rules for high-risk systems once it deploys them, including human oversight and a right to an explanation. Bound, but not yet triggered, because the material agentic deployment has not happened.
Add it up. Strong ambition, voluntary or partial instruments, and no production system that audits an agent's decision to the bar a citizen-affecting decision deserves. That gap is layer 5. On this model, that gap binds.
The United Kingdom is worth a careful word, because it is easy to over-read. It has put AI into benefits work at scale, in tools that help humans rather than decide alone. It has also picked up real accountability trouble while doing so: findings of biased outcomes, complaints about opacity, and reports from rights groups about harm to disabled and marginalised people.
That is not proof of anything about the agentic stage, because the United Kingdom has not reached the agentic stage. These are human-assist systems. The model reads the United Kingdom as an early warning, not as evidence of the agent layer. If the failures already show up at the gentler stage, the case for getting oversight right before the agent stage gets stronger.
Finland, of the places reviewed for the model, is the one that answered the oversight question with law first, before deploying at agentic scale. Its 2023 rules let public bodies use automated decision-making, but only where the decision rules are set in advance and officially approved.
That requirement quietly rules learning AI out of public-sector decisions. A learning system changes its own rules as it goes, so it cannot meet a set-in-advance-and-approved test. The Finnish customs agency says it plainly on its own page: learning AI techniques are not used. The chain is worth reading carefully. The law regulates automated decisions and the rules behind them. The exclusion of learning AI is how the agencies and legal scholars read and apply that law. Finland is not a "no AI" country. It uses AI in plenty of other ways. It has drawn a clear line around the one place that matters most: decisions about people.
New Zealand passed a law on 30 May 2026 letting the Ministry of Social Development approve automated decisions in social security. The Ministry was clear it means rules-based decisions, not generative AI. The model treats this as the easy case, and a good place to get layer 5 right. Rules-based decisions have an explicit rule behind every outcome. That is more inspectable than a human queue, not less. The opportunity is to turn that hidden inspectability into something a claimant, an auditor, or a tribunal can actually see and contest. The opposition's sharpest points in the debate were about transparency, and that is exactly the layer-5 work to do well.
The strength of a position depends on whether it can be checked. Here is the test, with the date Boost is measuring from.
As of Boost's last full review of the field, on 22 May 2026, no jurisdiction had shipped a material-scale agentic government deployment, multi-million citizens affected, or statutory authority over a real right, at the decision tier, without building the oversight to match. From that snapshot date forward, the test is this. If a jurisdiction ships an agent making citizen-affecting decisions at that scale, with no agent registry, no rules as code, and no audit trail at the Estonian bar, and runs it for at least eighteen months with no serious accountability failure, public-trust crisis, or court reversal, and if that pattern then repeats in two or more comparable countries, the position is wrong. Boost will say so if it happens. As of writing, it has not.
A few cautions on the argument itself.
The test is strict. Eighteen months, material scale, real decisions. A critic could say the bar is set so high it cannot fail. The reply is that it is the same bar the model would be judged against. If the bar is wrong, the whole reading is wrong, and the model would rather be checkable than safe.
"Material scale" is a judgement call, and reasonable people will draw it in different places, especially for chat-style front doors that serve many people without making real decisions.
Proving a negative is hard. Saying a country does not have an agent registry takes a real search that comes up empty, not just a search not yet done. The model marks the difference where it can.
And the view is narrow. The countries the model leans on, Estonia, the United Kingdom, New Zealand, Finland, plus Singapore, are mostly European or Anglo. A wider scan might show a different pattern. This is where the evidence actually sits.
On this reading, layer 5 is the part that decides whether any of the rest works safely, and it is the layer most commentary skips. This is also where Boost has standing to talk. Boost builds government digital services for a living, under real accountability rules. That is what production-grade oversight looks like up close, and it is what makes it possible to tell when a proposed system does not have it.
The series ends here. The model stands as five parts, not five rungs. Whether agentic government works depends most on the two layers that get the least attention: the foundation underneath, and the inspector at the top.

